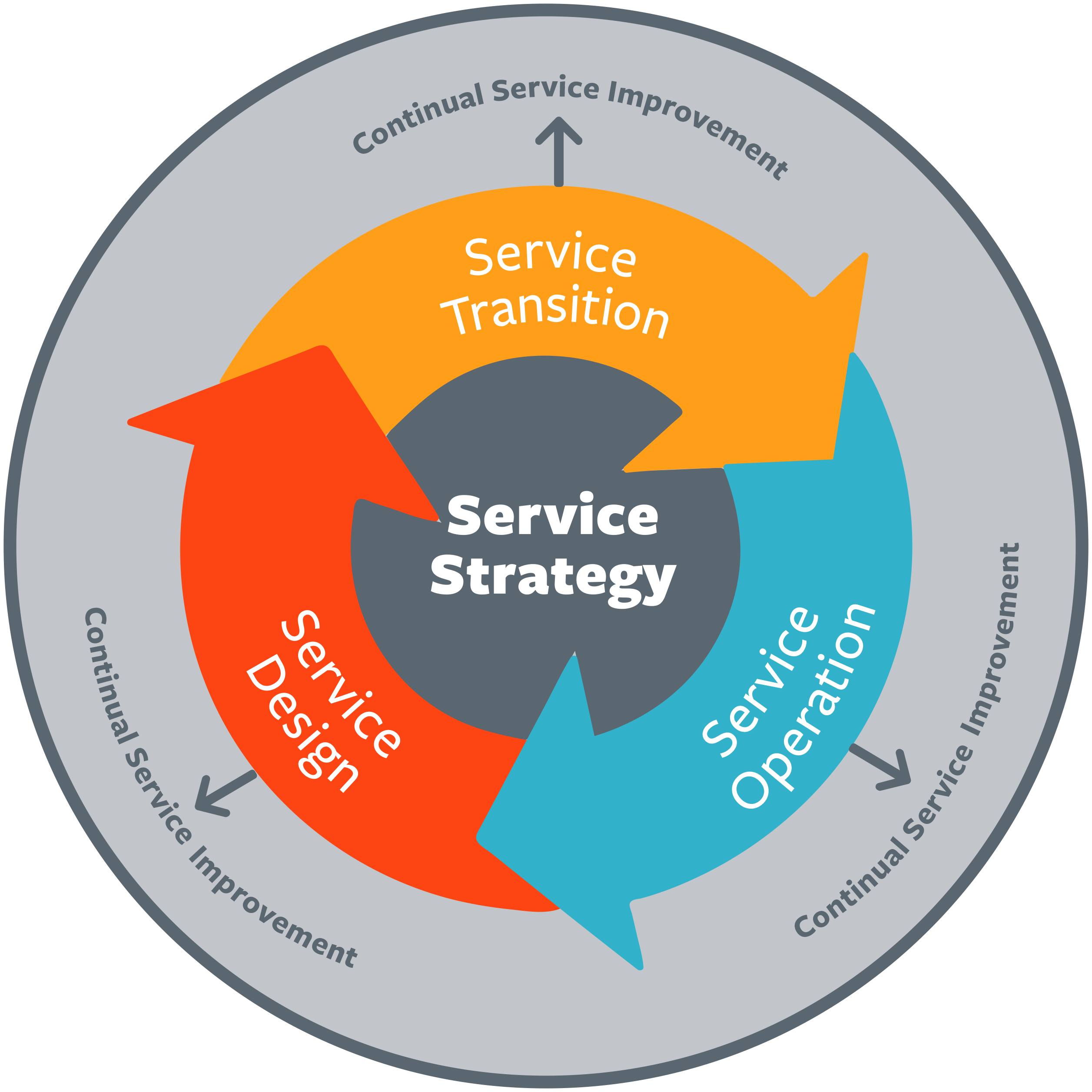
Service Strategy: Стратегия услуги (или Построение стратегии) – основа жизненного цикла услуги. Соответствующая ему публикация обозначает фундаментальность понятия сервис-менеджмента в контексте жизненного цикла услуги.
Service Strategy: Стратегия услуги (или Построение стратегии) – основа жизненного цикла услуги. Соответствующая ему публикация обозначает фундаментальность понятия сервис-менеджмента в контексте жизненного цикла услуги.
Стратегия сервиса (услуги)- является основой жизненного цикла услуги.
Центральным и ключевым термином ITIL является Сервис (Service), который в русскоязычной литературе часто называют услугой.
Data Structures and Algorithms
Асимптотический анализ
Измерение сложности алгоритмов - анализ времени, которое потребуется для обработки данных.При этом точное время мало кого интересует: оно зависит от процессора, типа данных, языка программирования и множества других параметров. Важна лишь асимптотическая сложность, т. е. сложность при стремлении размера входных данных к бесконечности.
Основные оценки роста, встречающиеся в асимптотическом анализе:
Пусть n – величина объема данных. Тогда рост функции алгоритма f(n) можно ограничить функций g(n) асимптотически:
| Обозначение | Описание |
| f(n) ∈ Ο(g(n)) | f ограничена сверху функцией g с точностью до постоянного множителя |
| f(n) ∈ Ω(g(n)) | f ограничена снизу функцией g с точностью до постоянного множителя |
| f(n) ∈ Θ(g(n)) | f ограничена снизу и сверху функцией g |
Например, время уборки помещения линейно зависит от площади этого самого помещения (Θ(S)), т. е. с ростом площади в n раз, время уборки увеличиться также в n раз. Поиск имени в телефонной книге потребует линейного времени Ο(n), если воспользоваться алгоритмом линейного поиска, либо времени, логарифмически зависящего от числа записей (Ο(log2(n))), в случае применения двоичного поиска.
Для нас наибольший интерес представляет Ο-функция. Кроме того, в последующих главах, сложность алгоритмов будет даваться только для верхней асимптотической границы.
Под фразой «сложность алгоритма есть Ο(f(n))» подразумевается, что с увеличением объема входных данных n, время работы алгоритма будет возрастать не быстрее, чем некоторая константа, умноженная на f(n).
Важные правила асимптотического анализа:
| Ο(k*f) = Ο(f) | постоянный множитель k (константа) отбрасывается, поскольку с ростом объема данных, его смысл теряется, например: Ο(9,1n) = Ο(n) |
| Ο(f*g) =Ο(f)*Ο(g) | оценка сложности произведения двух функций равна произведению их сложностей, например: Ο(5n*n) = Ο(5n)*Ο(n) = Ο(n)*Ο(n) = Ο(n*n) = Ο(n2) |
| Ο(f/g)=Ο(f)/Ο(g) | оценка сложности частного двух функций равна частному их сложностей, например:Ο(5n/n) = Ο(5n)/Ο(n) = Ο(n)/Ο(n) = Ο(n/n) = Ο(1) |
| Ο(f+g) | равна доминанте Ο(f) и Ο(g)оценка сложности суммы функций определяется как оценка сложности доминанты первого и второго слагаемых, например:Ο(n5+n10) = Ο(n10) |
Порядок роста
Порядок роста описывает то, как сложность алгоритма растет с увеличением размера входных данных. Чаще всего он представлен в виде Ο-нотации (от нем. «Ordnung» — порядок) : Ο(f(x)), где f(x) — формула, выражающая сложность алгоритма. В формуле может присутствовать переменная n, представляющая размер входных данных.
Константный — Ο(1)
Порядок роста O(1) означает, что вычислительная сложность алгоритма не зависит от размера входных данных. Следует помнить, однако, что единица в формуле не значит, что алгоритм выполняется за одну операцию или требует очень мало времени. Он может потребовать и микросекунду, и год. Важно то, что это время не зависит от входных данных.
Линейный — O(n)
O(n) — линейная сложность
Такой сложностью обладает, например, алгоритм поиска наибольшего элемента в не отсортированном массиве. Нам придётся пройтись по всем n элементам массива, чтобы понять, какой из них максимальный.
Логарифмический – O( log n)
O(log n) — логарифмическая сложность
Простейший пример — бинарный поиск. Если массив отсортирован, мы можем проверить, есть ли в нём какое-то конкретное значение, методом деления пополам. Проверим средний элемент, если он больше искомого, то отбросим вторую половину массива — там его точно нет. Если же меньше, то наоборот — отбросим начальную половину. И так будем продолжать делить пополам, в итоге проверим log n элементов.
Линеарифметический — O(n·log n)
Линеарифметический (или линейно-логарифмический) алгоритм имеет порядок роста O(n·log n). Некоторые алгоритмы типа «разделяй и властвуй» попадают в эту категорию. В следующих частях мы увидим два таких примера — сортировка слиянием и быстрая сортировка.
Квадратичный — O(n2)
O(n2) — квадратичная сложность
Такую сложность имеет, например, алгоритм сортировки вставками. В канонической реализации он представляет из себя два вложенных цикла: один, чтобы проходить по всему массиву, а второй, чтобы находить место очередному элементу в уже отсортированной части. Таким образом, количество операций будет зависеть от размера массива как n * n, т. е. n2.
Наилучший, средний и наихудший случаи
Что мы имеем в виду, когда говорим, что порядок роста сложности алгоритма — O(n)? Это усредненный случай? Или наихудший? А может быть, наилучший?
Обычно имеется в виду наихудший случай, за исключением тех случаев, когда наихудший и средний сильно отличаются. К примеру, мы увидим примеры алгоритмов, которые в среднем имеют порядок роста O(1), но периодически могут становиться O(n) (например, ArrayList.add). В этом случае мы будем указывать, что алгоритм работает в среднем за константное время, и объяснять случаи, когда сложность возрастает.
Самое важное здесь то, что O(n) означает, что алгоритм потребует не более n шагов.

Источники:
https://tproger.ru/translations/algorithms-and-data-structures/
https://tproger.ru/articles/computational-complexity-explained/
http://kvodo.ru/asymptotic-analysis.html
Дополнительные полезные материалы:
https://www.lektorium.tv/lecture/13926